ANR MDCA Passage
L'action PASSAGE vise à « Produire des
Annotations Syntaxiques à Grande Échelle»
pour aller de l'avant et est une action avalisée dans
le cadre de l'appel 2006
ANR MDCA «Masses de Données / Connaissances
Ambiantes ».
PASSAGE est prévue de début 2007 à
fin 2009
Objectifs
Les motivations principales de la proposition PASSAGE
sont doubles:
- améliorer la précision
et la robustesse des analyseurs syntaxiques existants pour
le français, en les utilisant sur de gros corpus
(plusieurs millions de mots) et
- exploiter les annotations syntaxiques
résultantes pour créer des ressources
linguistiques plus riches et plus extensives.
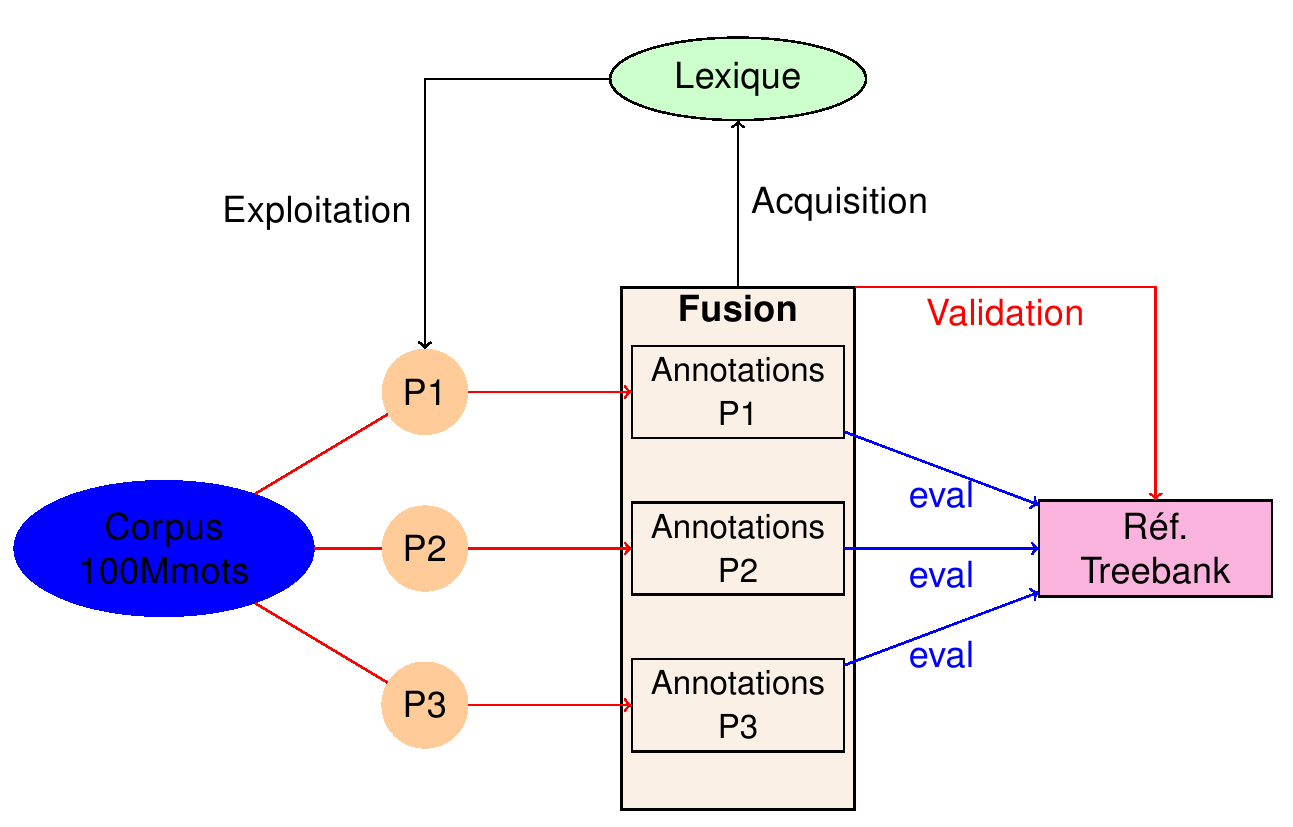
La méthodologie adoptée consiste en une boucle
de rétroaction (feedback) entre analyse
syntaxique et création de ressources, comme suit:
- l'analyse syntaxique est
utilisée pour créer des annotations
syntaxiques
- les annotations sont utilisées
pour créer ou enrichir des ressources linguistiques
comme des lexiques, grammaires ou corpus annotés
- les ressources créées ou
enrichies sur la base des annotations sont ensuite
intégrées dans les systèmes
d'analyse.
- les analyseurs enrichis sont
utilisés pour créer des ressources encore plus
riches (par exemple syntactico-sémantiques)
- etc.
Plus généralement, le projet PASSAGE
devrait aussi aider à faire émerger des
chaînes de traitement linguistique exploitant des
informations lexicales plus riches, en particulier
sémantiques.
PASSAGE s'appuie sur les résultats de la
campagne d'évaluation des analyseurs syntaxiques
menée dans le cadre de l'action EASy/EVALDA
[http://www.technolangue.net/article198.html]
(programme Technolangue). Cette campagne a montré que
plusieurs systèmes d'analyse existent désormais
pour le Français. Néanmoins, bien que les
résultats furent meilleurs que prévus, cette
campagne a confirmé que la robustesse et la
précision peuvent encore être largement
améliorées, en particulier pour les données
orales.
De plus, bien que le plan initial de EASy était
de combiner les résultats produits par chaque participant
pour construire une treebank du Français (un corpus
annoté syntaxiquement), cette phase reste à venir,
et le résultat, malgré son intérêt
certain, restera relativement limité (environ 40K phrases
avec un sous-ensemble de 4K phrases manuellement
validées), au regard des standards internationaux qui
émergent (10M à 100M mots, i.e. 0.5M à 5M
phrases).
PASSAGE vise à poursuivre et à
étendre la ligne de recherche initiée par la
campagne EASy. En particulier, PASSAGE cherche
à:
- organiser des nouvelles campagnes
d'évaluation pour évaluer et améliorer les
systèmes d'analyse syntaxiques du Français sur de
gros corpus (millions de mots)
- finaliser une méthodologie pour
comparer et fusionner les résultats fournis par
plusieurs analyseurs
- utiliser les résultats
fusionnés des meilleurs analyseurs pour construire une
treebank du Français
- valider cette treebank soit manuellement
soit automatiquement
- utiliser à la fois cette treebank
et la partie non-validée du gros corpus annoté
syntaxiquement pour extraire des informations
linguistiques
- intégrer les ressources ainsi
acquises dans les analyseurs
- développer les
méthodologies pour évaluer la qualité des
ressources ainsi acquises
La participation d'une dizaine systèmes d'analyse
syntaxique dans un effort collectif tourné vers
l'acquisition de ressources linguistiques est un occasion
plutôt unique et augmentant les chances de succès de
PASSAGE.
- Prochaine réunion le 11 F�vrier 2008
- tenue du workshop international "Automated Syntactic
Annotations for Interoperable Language Resources" (Hong-Kong, 8
Janvier 2008) organisé sous les auspices de ISO dont les
thèmes recoupent largement ceux de Passage. Ce workshop
prend place dans le cadre de la conférence IGCL'08 . Pr�sentation de 3
articles reli� � Passage.
- Cl�ture de la campagne d'�valuation au 21 D�cembre
2007.
- Présentation de Passage au Grand Colloque STIC 2007
(présentation, poster et démonstration de
EasyRef, un service WEB pour la gestion collaborative
d'annotations syntaxiques à la EASy)
- Première campagne d'évaluation syntaxique
(dans la lignée d'EASy) en Octobre 2007
- Réunion de lancement le 17 Janvier 2007.
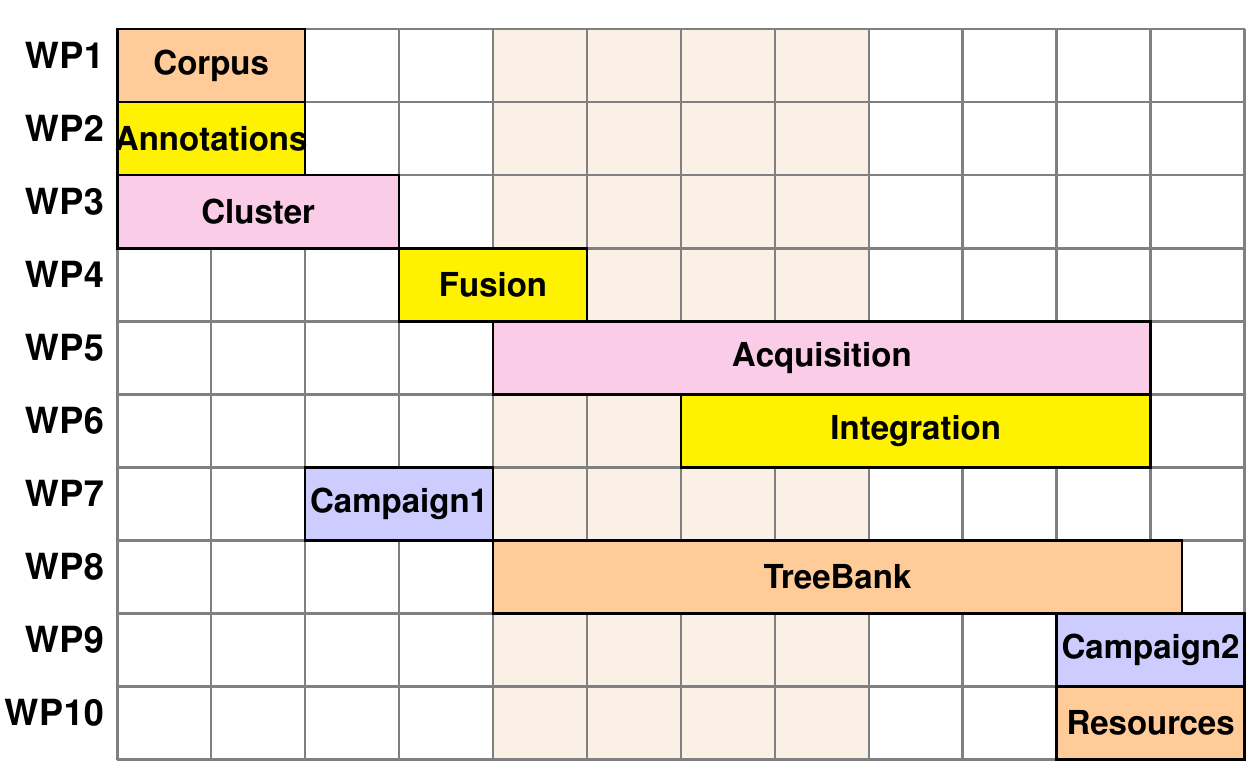
- WP1 Identification et préparation des
corpus
- WP2 Standards et infrastructure pour les
annotations
- WP3 Traitement à large échelle sur
cluster
- WP4 Comparaison et fusion d'annotations
syntaxiques
- WP5 Acquisition de ressources lexicales à
partir d'annotations
- WP6 Intégration et validation des ressources
lexicales
- WP7 Première campagne
d'évaluation
- WP8 Sous-corpus de références
manuellement validé pour les annotations
- WP9 Seconde campagne d'évaluation
- WP10 Préparation des ressources, corpus et
documentation pour distribution
| |
Libellé |
Type |
Date |
|
2 |
Initial Repository |
online database |
T06 |
|
4 |
Intermediary Documentation |
report |
T12 |
|
5 |
Report evaluation camp. 1 |
report |
T12 |
|
8 |
Reference subcorpus |
database |
T24 |
|
9 |
Acquired Lexical Resources
(intermediate version) |
database |
T24 |
|
10 |
Report on Acquisition |
report |
T24 |
|
13 |
Final Report |
report |
T36 |
|
14 |
ROVER Corpus |
online database |
T36 |
|
15 |
Treebank toolkit mgmt. |
software |
T36 |
|
16 |
Report evaluation camp. 2 |
report |
T36 |
|
17 |
Evaluation package |
software |
T36 |
|
18 |
Report on Propbank
experiment |
report |
T36 |
|
19 |
Semantic parser |
software |
T36 |
|
20 |
Acquired Lexical Resources |
database |
T36 |
Sur les banques
d'annotations (treebank) :
Sur «bootstrapper» des ressources à
partir d'annotations
Sur les plateformes et standards d'annotation
Bibliographie
De la Clergerie
Eric