11 Handling ambiguities
Table of contents
Ambiguities naturally arise when handling natural language, and especially for automatically produced annotations. Ambiguities may occur at various levels and, therefore, MAF proposes several alternatives to cope with ambiguities as simply as possible.
11.1 Word form Content AmbiguitiesISO: Word form Content Ambiguities¶
The proposal on Feature Structure Representation provides several ways to represent ambiguities, for instance at the level of feature values. These mechanisms may be used to handle the ambiguities occurring within the morpho-syntactic content of a word-form.
For instance, the French inflected verb form “mange” (to eat) is ambiguous between the 1st and 3rd persons, and this ambiguity can be captured by the vAlt element present in FSR:
<wordForm tokens="t0" entry="urn:lexicon:fr:manger">
<fs>
<f name="pos">
<symbol value="verb"/>
</f>
<f name="aux">
<symbol value="avoir"/>
</f>
<f name="mood">
<symbol value="indicative"/>
</f>
<f name="tense">
<symbol value="present"/>
</f>
<f name="person">
<vAlt>
<symbol value="first"/>
<symbol value="third"/>
</vAlt>
</f>
<f name="number">
<symbol value="singular"/>
</f>
</fs>
</wordForm>
A compact tag notation can still be used by registering most frequent cases of ambiguities in FSR libraries (Section 8.2.1).
<wordForm
tokens="t0"
entry="urn:lexicon:fr:manger"
tag="pos.v aux.avoir mood.i tense.p pers.13 num.s"/>
11.2 Lexical AmbiguitiesISO: Lexical Ambiguities¶
Ambiguities between different lexical entries for a same sequence of tokens can be handled by the element wfAlt:
<wfAlt>
<wordForm tokens="t0" entry="lexicon:porte" tag="pos.n ..."/>
<wordForm tokens="t0" entry="lexicon:porter" tag="pos.v ..."/>
</wfAlt>
11.3 Structural AmbiguitiesISO: Structural Ambiguities¶
11.3.1 Structural ambiguities over word formsISO: Structural ambiguities over word forms¶
A general and very generic answer is to describe the possible readings as paths through an Directed Acyclic Graph (DAG) whose edges are labeled by a word form. Such DAGs forms a sub-part of Finite State Automata and also cover the notion of word lattice used in parsing and speech recognition communities. They are powerful enough to represent ambiguities between several decompositions into compound forms. They can also be used to denote simpler cases of lexical ambiguities.
For instance, the French textual sequence “fer à cheval” (horse shoe) can still be decomposed into several readings (“'’, “[iron] [on horse]”, “'’), giving the following DAG:
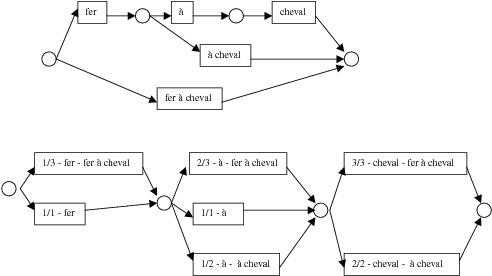 Figure 3
Figure 3<token id="t2">à</token>
<token id="t3">cheval</token>
<fsm init="S0" final="S3">
<transition source="S0" target="S3">
<wordForm
tokens="t1 t2 t3"
entry="urn:lex:fr:fer_%E0_cheval"
lemma="fer_à_cheval"/>
</transition>
<transition source="S0" target="S1">
<wordForm entry="urn:lex:fr:fer" tokens="t1"/>
</transition>
<transition source="S1" target="S2">
<wordForm tokens="t2" entry="urn:lex:fr:%E0" lemma="à"/>
</transition>
<transition source="S2" target="S3">
<wordForm tokens="t3" entry="urn:lex:fr:cheval"/>
</transition>
<transition source="S1" target="S3">
<wordForm tokens="t2 t3" entry="urn:lex:fr:%E0_cheval" lemma="à_cheval"/>
</transition>
</fsm>
The linguistic units “fer à cheval”, “fer”, “à”, “cheval”, and “à cheval” correspond to minimal syntagmatic units that can be annotated.
Additional information could be added to edges such as probabilities.
11.3.2 Structural ambiguities over tokensISO: Structural ambiguities over tokens¶
Structural ambiguities may also arise over sequences of tokens, resulting from ambiguities in the tokenization of the annotated document, e.g. speech documents.
Structural ambiguities over tokens are represented by transitions labeled by tokens. The attributes tinit and tfinal on elements fsm are used to state the initial and final states for the token paths.
The two levels of structural ambiguities are represented by two lattices that form a kind of chart. It is not mandatory but advised that the two lattices share their states, whenever possible.
A validity condition has to be expressed between the two levels of structural ambiguity:
the tokens covered by word forms along a word form path belong to some token path.
11.4 Simplified structuring variantsISO: Simplified structuring variants¶
11.4.1 Non ambiguous linear representationISO: Non ambiguous linear representation¶
When there is no ambiguity, MAF allows to replace the global lattice notation by a much simpler linear notation where the token, wordForm and wfAlt elements are implicitly chained following their appearance order, as illustrated by the following example:
<token id="t2">à</token>
<token id="t3">cheval</token>
<wordForm entry="urn:lex:fr:fer" tokens="t1"/>
<wordForm entry="urn:lex:fr:%E0" tokens="t2"/>
<wordForm entry="urn:lex:fr:cheval" tokens="t3"/>
11.4.2 Mixed linear and lattice representationISO: Mixed linear and lattice representation¶
Ambiguities are generally localized and it is tempting to also localize the use of the lattice notation only where it is needed. MAF allows to insert local lattice fsm in a linear flow of token, wordForm and wfAlt elements.
<token id="t1">de</token>
<fsm init="s0" final="s2">
<transition source="s0" target="s2">
<wordForm tokens="t0 t1" entry="urn:lex:fr:afin_de" tag="pos.prep"/>
</transition>
<transition source="s0" target="s1">
<wordForm tokens="t0" entry="urn:lex:fr:afin" tag="pos.prep"/>
</transition>
<transition source="s1" target="s2">
<wordForm tokens="t1" entry="urn:lex:fr:de" tag="pos.prep"/>
</transition>
</fsm>
<token id="t2">grandir</token>
<wordForm entry="urn:lex:fr:grandir" tag="pos.verb ..." tokens="t2"/>
<token id="t3">,</token>
<wordForm entry="lexicon:," tag="pos.ponct" tokens="t3"/>
<token id="t4">il</token>
<wordForm entry="urn:lex:fr:il" tag="pos.pronoun ..." tokens="t4"/>
<token id="t5">mange</token>
<wordForm tokens="t5" entry="urn:lex:fr:manger" tag="pos.verb ..."/>
<token id="t6">des</token>
<wordForm
tokens="t6"
entry="urn:lex:fr:une"
form="des"
tag="pos.det num@pl ..."/>
<token id="t7">pommes</token>
<token id="t8">de</token>
<token id="t9">terre</token>
<fsm init="s8" final="s11">
<transition source="s8" target="s11">
<wordForm
tokens="t7 t8 t9"
entry="urn:lex:fr:pomme_de_terre"
tag="pos.noun ..."/>
</transition>
<transition source="s8" target="s9">
<wordForm tokens="t7" entry="urn:lex:fr:pomme" tag="pos.noun ..."/>
</transition>
<transition source="s9" target="s10">
<wordForm tokens="t8" entry="urn:lex:fr:de" tag="pos.prep"/>
</transition>
<transition source="s10" target="s11">
<wordForm tokens="t9" entry="urn:lex:fr:terre" tag="pos.noun ..."/>
</transition>
</fsm>
11.5 Expanding the simplified variantsISO: Expanding the simplified variants¶
The simplified variants are allowed because they may always be expanded into a global lattice, by applying the steps sketched in the following sub-sections.
11.5.1 Separating tokens and word formsISO: Separating tokens and word forms¶
All tokens embedded within a word form may be extracted and moved just before the word form (and before an enclosing wfAlt) , not changing the relative order between tokens.
<token id="t6">des</token>
</wordForm>
becomes
<wordForm entry="urn:lex:fr:manger" tag="pos.verb ..." tokens="t6"/>
Note: There is no clear semantic to handle tokens embedded in word forms, themselves embedded in transitions. This case should be avoided.
11.5.2 Wrapping into local latticesISO: Wrapping into local lattices¶
Tokens and word forms outside transitions are embedded into local lattices, wfAlt elements being considered as word forms.
<wordForm entry="urn:lex:fr:il" tag="pos.pronoun ..." tokens="t4"/>
<token id="t5">mange</token>
<wordForm entry="urn:lex:fr:manger" tag="pos.verb ..." tokens="t5"/>
<token id="t6">des</token>
becomes
tinit="s0"
tfinal="s1"
init="s0"
final="s0">
<transition source="s0" target="s1">
<token id="t4">il</token>
</transition>
</fsm>
<fsm
init="s0"
final="s1"
tinit="s0"
tfinal="s0">
<transition source="s0" target="s1">
<wordForm entry="urn:lex:fr:il" tag="pos.pronoun ..." tokens="t4"/>
</transition>
</fsm>
<fsm
tinit="s0"
tfinal="s1"
init="s0"
final="s0">
<transition source="s0" target="s1">
<token id="t5">mange</token>
</transition>
</fsm>
<fsm
init="s0"
final="s1"
tinit="s0"
tfinal="s0">
<transition source="s0" target="s1">
<wordForm entry="urn:lex:fr:manger" tag="pos.verb ..." tokens="t5"/>
</transition>
</fsm>
Lattice states are local to each lattice.
11.5.3 Merging local latticesISO: Merging local lattices¶
Two adjacent lattices may be merged by renaming the intermediary states in order to avoid name clashes and in such a way that the word form (resp. token) final state of the first lattice equals the word form (resp. token) initial state of the second lattice. Whenever possible, it is recommended, when merging, to rename the lattice states in such a way that the final (resp. final) states for tokens and word form coincide.
The previous example becomes:
tinit="s0"
tfinal="s1"
init="s0"
final="s1">
<transition source="s0" target="s1">
<token id="t4">il</token>
</transition>
<transition source="s0" target="s1">
<wordForm entry="urn:lex:fr:il" tag="pos.pronoun ..." tokens="t4"/>
</transition>
</fsm>
<fsm
tinit="s0"
tfinal="s1"
init="s0"
final="s1">
<transition source="s0" target="s1">
<token id="t5">mange</token>
</transition>
<transition source="s0" target="s1">
<wordForm entry="urn:lex:fr:manger" tag="pos.verb ..." tokens="t5"/>
</transition>
</fsm>
and then
tinit="s0"
tfinal="s2"
init="s0"
final="s2">
<transition source="s0" target="s1">
<token id="t4">il</token>
</transition>
<transition source="s0" target="s1">
<wordForm entry="urn:lex:fr:il" tag="pos.pronoun ..." tokens="t4"/>
</transition>
<transition source="s1" target="s2">
<token id="t5">mange</token>
</transition>
<transition source="s1" target="s2">
<wordForm entry="urn:lex:fr:manger" tag="pos.verb ..." tokens="t5"/>
</transition>
</fsm>
11.5.4 Removing wfAltISO: Removing wfAlt¶
A transition over a lexical ambiguity, materialized by a wfAlt element, may be expanded into two equivalent simpler transitions.
<wfAlt>
<wordForm tokens="t0" entry="lexicon:porte" tag="pos.noun ..."/>
<wordForm tokens="t0" entry="lexicon:porter" tag="pos.verb ..."/>
</wfAlt>
</transition>
<transition source="s0" target="s1">
<wordForm tokens="t0" entry="urn:lex:fr:porte" tag="pos.noun ..."/>
</transition>
<transition source="s0" target="s1">
<wordForm tokens="t0" entry="urn:lex:fr:porter" tag="pos.verb ..."/>
</transition>
</fsm>
The ordering of transitions inside lattices is not pertinent. On the other hand, the ordering of word forms and tokens outside lattices is pertinent. The relative ordering of local lattices is also pertinent.
11.6 Formal description: wfAlt and fsmISO: Formal description: wfAlt and fsm¶
- fsm (Finite State Machine)
Used to describe an ambiguous flow of token
and/or wordForm elements
init init state of the FSM wrt wordForms final final state of the FSM wrt wordForms tinit init state of the FSM wrt tokens tfinal final state of the FSM wrt tokens - transition
FSM transition in a flow of tokens and/or wordForms
source source state of a transition target target state of a transition - wfAlt ( WordForm Alternative) Simplified form to express an alternative between several word forms
↑ Contents « 10 Morpho-syntactic content » 12 Header and metadata